
Non-Human Identity for AI Agents: The New IAM Frontier
our IAM wasn't built for machines that think. How non-human identity for agents works - and the controls that actually scale.

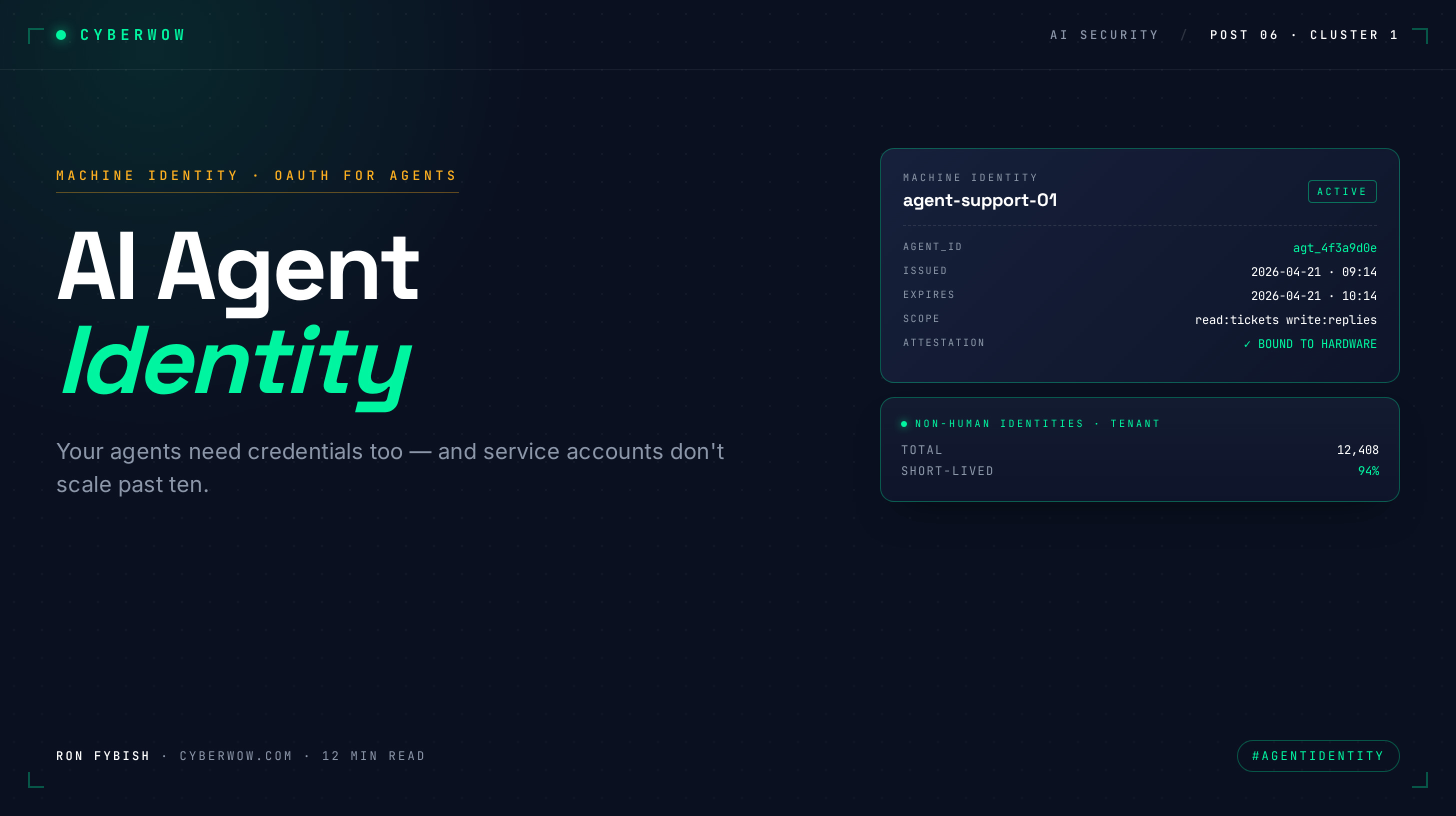
Your IAM system has humans and service accounts. Humans are provisioned on day one, have passwords or SSO, get deprovisioned when they leave. Service accounts are for integrations: API keys, OAuth tokens, occasionally mTLS certificates. They don’t require password resets and usually don’t expire.
An AI agent is neither. It’s not a human, it doesn’t have a human operator managing it in the traditional sense. But it’s also not a service account, its behavior is non-deterministic, depends on model outputs and external context, and changes in ways the static provisioning of a service account doesn’t accommodate. When a service account behaves unexpectedly, the cause is usually misconfiguration or a breach. When an agent behaves unexpectedly, the cause could be a prompt injection, a corrupted tool result, a hallucination, or a legitimate logic error in the planning. Your IAM can’t tell the difference and can’t respond intelligently.
This is the problem non-human identity (NHI) is supposed to solve. And it’s a real problem: the faster agents proliferate, the faster your identity and access management system breaks down. This guide explains what NHI architecture looks like, what vendors are building it, and the controls that actually reduce risk at scale.

Why human IAM breaks for AI agents
Three assumptions in traditional IAM fail for agents:
Assumption 1: Identity is tied to a human accountholder. Traditional IAM is built around the idea that every identity corresponds to a human person who can be held responsible for their actions. When an employee’s account takes an action, we log “employee X did Y” and can later interview employee X. With agents, there’s no human to interview. The agent takes an action because a model decided to, based on inputs that may have been poisoned by an attacker. Log-based accountability still works, but the inference chain is different, and most SIEM rules aren’t built to trace causality through model decisions.
Assumption 2: Trust is established once at provisioning time. When you provision a service account, you establish its identity through a shared secret (an API key) or a certificate. From that point on, every request from that service account is trusted because we assume the secret is secure. Agents break this assumption because an agent can be compromised by a prompt injection without its credentials being compromised. The agent’s API key is still valid, but the agent’s behavior is now attacker-controlled. Your IAM can’t distinguish a compromised agent (behavior changed by prompt injection) from a legitimately-updated agent (behavior changed by the engineering team).
Assumption 3: Access is static between provisioning and deprovisioning. A service account’s permissions don’t change unless someone explicitly changes them. Agents, especially autonomous agents in large systems, benefit from contextual access control: the agent’s effective permissions should depend on what it’s trying to do, what tools are available, and what rate limits apply. A hiring agent should have read-only access to candidate profiles but read-write access to an applicant-tracking system, and both should be scoped to the job posting it’s evaluating. When the job posting closes, those permissions should vanish. Static IAM can provision the initial access, but it can’t dynamically narrow permissions per-task.
None of these are insurmountable. But they require rethinking the control surface.

The four dimensions of AI agent identity
Non-human identity for agents breaks down into four claims, each one a control plane with its own implementation choices:
Principal. Who is this agent acting as? Not “who built it” but “whose authorization scope is it exercising?” An agent running on behalf of recruiter_alice needs a different set of permissions than one running autonomously in a background job. The principal claim is core to any identity, it answers “whose access are we granting here?”
Intent. What task or scope is authorized? This is narrower than role. The intent claim says “this agent is solving a hiring problem for job_id=J42, not general access to all candidate data.” Intent can be time-bound (”valid until the job closes”) or data-bound (”read-only”) or action-bound (”can prepare a candidate list but cannot extend an offer”). Most traditional IAM has no way to express intent; it stops at role.
Provenance. What model, version, and deployment is making this request? This matters for compliance (an agent running on your infrastructure is different from one running on third-party infrastructure) and for trust decisions (a GPT-4-based agent behaves differently from a GPT-3.5-based one). Provenance also includes whether the agent is running in a sandbox, a staging environment, or production.
Session. What is the parent request and correlation chain? If agent_a spawns agent_b to solve a subproblem, the entire chain becomes an audit trail. Session context lets you ask “who ultimately initiated this action?”, user or system? Human or autonomous?
Each claim maps to a control decision in modern auth frameworks. A complete agent identity system captures all four.
1. Authentication: How does the agent prove it is who it claims?
When an agent makes a request to a tool, it needs to prove its identity. Four mechanisms are in active use:
Shared secrets (API keys). Simple, works everywhere. The agent stores a key and includes it with each request. Downside: keys don’t expire, live in plaintext configuration, and can’t distinguish a legitimate request from an attacker-controlled one using the same key. Right for low-risk integrations; wrong for production.
OAuth 2.1 client-credentials. The agent authenticates to an authorization server with a client ID and secret, gets a short-lived token, and uses that token for tool calls. Advantages: credentials don’t leak into logs, rotation is straightforward, the auth server controls revocation. Disadvantages: requires an auth server, every tool call has added latency, token refresh failures require retry logic. Deployment cost is moderate; maturity is high.
SPIFFE/SPIRE. The agent gets a workload identity certificate signed by your SPIRE infrastructure. Every tool call uses mTLS with that certificate. Advantages: certificates have short lifespans (minutes), can encode rich context (agent name, team, task ID), support fine-grained revocation. Disadvantages: requires you to run SPIFFE/SPIRE, your tools must support mTLS, certificate management is an operational burden. Deployment cost is high; maturity varies (SPIFFE is CNCF-graduated but requires infrastructure investment).
Attested execution (AWS Nitro / Intel TDX / Azure Confidential Compute). The agent runs in a TEE, cryptographically proves the model running inside, and that attestation serves as the identity credential. This is the strongest mechanism, an attacker would need to compromise the hardware to forge it. Disadvantages: only available on certain cloud platforms, requires agents to run in TEE-compatible runtimes, adds compute overhead. Deployment cost is high; maturity is early but accelerating.
MechanismSimplicitySecurityExpirationCostMaturityAPI KeysHighLowNoneLowHighOAuth 2.1MediumHighHoursMediumHighSPIFFE/SPIRELowHighMinutesHighMediumAttested ExecutionLowVery HighHoursHighEarly
Best practice: Start with OAuth 2.1 for medium-to-high-risk agents. Migrate to SPIFFE/SPIRE if you own the agent infrastructure and need very short credential lifespans. Use attested execution for the highest-risk scenarios, once your infrastructure supports it.

1b. Authorization: Per-agent, per-intent policies
Authentication proves “I am agent_x.” Authorization answers “agent_x, acting on task T, may access resource R under condition C.” This is where most NIH deployments fall short.
Policy-as-code frameworks like OPA/Rego or AWS Cedar let you express per-agent, per-intent policies in a machine-checkable format. A simple example:
allow(principal, action, resource) :=
principal.type == "agent" and
principal.agent_type == "hiring" and
resource.resource_type == "candidate_profiles" and
resource.job_id in principal.authorized_job_ids and
resource.data_classification == "interview_safe" and
action in ["read", "score"];
This rule says: a hiring agent can read and score candidate profiles from approved job postings, but only those marked interview_safe in the schema. When a job posting closes, it drops from authorized_job_ids, and access automatically revokes. No manual policy changes required.
OPA and Cedar are both mature, open-source (or open and vendor-backed), and deployable on-prem or in the cloud. They integrate with API gateways, microservice frameworks, and IAM platforms. The operational cost is real but scales once you have a few dozen agents.

2. Authorization and scoping
Authentication says “you are who you claim.” Authorization says “given who you are, acting on what task, with what constraints, what are you allowed to do?”
For agents, the context-dependent part is critical. A hiring agent evaluating candidates for an Engineering Manager role needs read access to candidate profiles for that role, not all roles. Not to salary data. And only until the job closes. Static role-based IAM cannot express this.
Attribute-based access control (ABAC) handles this through conditional policies. You define attributes on the principal (agent_type, authorized_job_ids, current_scope) and the resource (job_id, data_classification, owner), then policies evaluate both. “agent_type == hiring AND job_id IN authorized_job_ids AND data_classification != salary THEN allow read on candidate_profiles.”
OPA/Rego and Cedar both support this out of the box. The implementation work is moderate: you identify the attributes that matter for your agents, add them to your authentication context, deploy a policy engine in your API gateway, and write the rules. A 90-day effort for a team of two. After that, adding new agents and new rules is days, not weeks.
Least-privilege in motion. The hard part isn’t authorization; it’s determining what “minimal access” actually means for an agent type you’ve never built before. Log what your hiring agent actually uses for 30 days. Read 5 fields from candidate profiles? Salary data? Job description? Use that log to set your baseline, then tighten any overly broad access. Repeat every 90 days as the agent evolves.
Best practice: Start with coarse roles and broad permissions. Instrument logging so you can see what each agent touches. At 20+ agents in production, formalize the policy layer (OPA or Cedar) and automate the review cycle.
3. Auditing: Access and decision traces
Audit logging for agents has two layers: access logs and decision logs. Most teams get the first wrong and skip the second.
Access logs are what your API gateway does: “agent_hiring_001 called /candidates?role=engineering_manager with token abc123 at 2026-04-19T14:03:22Z.” Aembit, Astrix, and Clutch sit between agents and tools and emit access logs automatically. These are table stakes; if you don’t have them, start there.
Decision logs are the reasoning trace: “Agent received task ‘rank candidates,’ queried 47 profiles, evaluated each with model X, returned scores, showed top 5 to user.” Access logs answer what the agent did. Decision logs answer why. When something goes wrong, you need both.
The practical problem: access logs are easy to capture at the infrastructure layer. Decision logs require the agent developer to instrument their code. Most developers don’t; they ship agents with print statements at best. The gap is real, and there’s no “buy a tool and solve this” option yet.
The audit trap in practice. When a hiring agent makes a discriminatory decision, access logs show it read candidate profiles. Decision logs show which fields it weighted heavily, whether it downscored people from certain regions, whether an attacker inserted a poisoned profile into the candidate list. Without decision logs, you can’t do root cause analysis. With them, you can replay the exact session.
For high-risk agents (hiring, lending, data deletion), require decision logging before deployment. For low-risk agents (summarization, lookup), access logs are usually enough. The decision is yours, but be explicit about it.
4. Revocation: Stopping agents fast
Revocation is the hard part almost nobody thinks about until there’s an incident.
When a service account is compromised, you delete its API key. Done in 60 seconds. When an agent is compromised, revoking it has three modes:
Immediate revocation stops the agent on its next request (credential check fails, request rejected). Fastest containment, highest disruption. Use when the agent is actively causing harm.
Graceful shutdown tells the agent “finish your current task, then stop.” Takes minutes or hours depending on task length. Use when you suspect compromise but want to avoid mid-task data corruption.
Quarantine routes the agent’s requests to a monitor instead of the actual tool. The agent thinks it’s working; you’re recording everything. Use when you want to observe what the agent would do without letting it.
Most scenarios: immediate revocation with a 30-second grace period (finish the current API call, then stop).
The harder problem is knowing when to revoke. You need behavioral detection: the agent making requests outside its normal scope, accessing sensitive data it usually ignores, or violating its authorization policy. This is where observability feeds into identity. Log at the decision level, build alerting on anomalies, tie alerts to revocation procedures.
Best practice: Document your revocation runbook before deploying. Test it quarterly. Know how long an incident-to-revocation sequence should take (target: under 5 minutes for high-risk agents).

Three failure modes most NHI vendors won’t mention
Before diving into the control options, three architectural mistakes are common enough to block: Know these before you build.
Agent-to-agent delegation without principal chaining. Agent A spawns Agent B to solve a subproblem. B needs credentials to act. The tempting mistake: give B the same credentials as A. Now if B is compromised, A is too. The right approach: B gets a new credential that chains back to A’s principal, with a narrower scope. The audit trail shows “A initiated, B executed on behalf of A.” B can’t do anything A couldn’t, but it also can’t do everything A could. The cost: orchestration infrastructure (Temporal, K8s, AWS Step Functions) that understands credential issuance per stage. Most teams skip this and regret it.
Long-lived service accounts every agent reuses. You create one service account called agent_pool_prod. Every agent in production uses it. Zero isolation. When one agent is compromised, all are. The fix: each agent gets its own credential, with its own identity, logging, and revocation. This creates operational overhead (more credentials to manage), but it’s a mandatory cost of having more than one agent in production.
Token theft from agent memory and logs. Agents store credentials in environment variables, config files, or in-memory state. Logs capture those credentials in error messages or debug output. An attacker who can read the agent’s environment, logs, or storage reads its credentials. Defense: never log credentials. Use a secrets vault (HashiCorp Vault, AWS Secrets Manager, GCP Secret Manager) and fetch credentials at runtime. Short-lived credentials (hours, not days) reduce the window. Never store credentials in the agent’s code.
Address these three before choosing your authentication mechanism. They’ll affect your architecture regardless of which option you pick.
Least-privilege in practice: The access audit loop
Authorization is where security work becomes real. Build or buy a tool that can show you: agent X called endpoint Y with parameters Z at time T. For 30 days, just observe.
For a hiring agent, you might see: reads candidate profiles (5 fields), reads job descriptions, calls the evaluation model, never touches salary data, never calls the refund API, never touches HR records outside recruiting.
Now you can write a policy: “hiring_agent can read candidate_profiles.{name, email, resume, job_id, years_experience}, can read job_descriptions, can call llm_evaluate, cannot call any other endpoints.” This is your “right” level.
The pattern across teams: start with a broad role, log for 30 days, set the policy based on what you see, then set an alert for any deviation. If hiring_agent tries to read salary data, alert. If it tries to call the refund API, block it immediately.
The feedback loop: Every 90 days, look at agent access logs. If a new job function appears (e.g., “hiring agents now evaluate writing samples too”), update the policy. If an agent is trying things outside its policy, investigate why. Is the policy wrong, or is the agent compromised?
This loop is operationally simple but requires discipline. Most teams skip it and regret it when an agent starts behaving strangely.
Building a non-human identity program: 90-day roadmap
Days 1–30: Inventory and audit. List every agent in your environment: internal builds, embedded in SaaS (GitHub Copilot Workspace, Slack AI, Salesforce Agentforce), running in production, in staging, local-only. For each: who built it, what data it touches, what tools it calls, current auth mechanism (usually API keys). Expect 15–40 agents depending on org size.
Days 31–60: Risk-tier and threat-model. For each agent, ask: what’s the blast radius if it’s fully compromised? Can it delete data? Transfer money? Exfiltrate customer records? High-risk agents get the control investment. Medium and low get lighter treatment. For high-risk agents, apply the threat-model questions from the Pillar 2 guide: who influences its context, which tools have irreversible effects, what does it remember.
Days 61–90: Control implementation. For high-risk agents, migrate from API keys to short-lived credentials (OAuth 2.1, SPIFFE/SPIRE, or cloud-native identity like AWS IAM). Set up decision logging (instrument the agent code or use a proxy that captures full request traces). Write an authorization policy for each high-risk agent (use OPA/Rego if you have it; use your IAM vendor’s policy language otherwise). Document your revocation process in your IR playbook and test it.
By day 90, you should know: - Every agent in your environment - Which ones are high-risk - What credentials they use - What they’re authorized to access - How to revoke them if needed - What logs you have and how long you retain them
This is defensible ground. It’s not complete (you haven’t automated the access review loop yet, ABAC is still a future phase, behavioral detection is minimal), but it’s a stable foundation.
The next 90–180 days: OPA/Cedar policies, mTLS in the thick client cases, quarterly red teaming of agent workflows, anomaly detection on agent behavior, and automated access review.
Vendor landscape for non-human identity
The market for dedicated NHI is nascent but populated. Here’s the angle each player takes:
Aembit, zero-trust machine identity. Focuses on short-lived credentials and passwordless authentication for agents and service accounts. Emphasizes the “zero-trust” framing.
Astrix, supply chain focus. Verifies the identity of agents and services that belong to your vendor ecosystem, not just internal agents. Useful if you’re distributing agents to customers.
Clutch, agent-specific IAM. Sits between agents and tools, captures logs, and provides fine-grained access control per agent. Early but well-funded.
Oasis, policy-as-code for ML/AI workloads. Similar to Cedar/OPA but with ML-specific extensions (model versioning, dataset lineage).
Entro, workload identity for Kubernetes and cloud. Not agent-specific but handles the infrastructure layer that agents run on.
Orchid, behavioral identity for APIs. Uses model-based behavior analysis to detect anomalies and suspicious agent behavior.
Token, secrets management for AI. Focuses on credential rotation and injection for agent workloads. Similar to Vault but agent-native.
Natoma, agent audit and replay. Captures agent sessions and lets you replay them for compliance and debugging.
For most teams, the answer is “don’t buy a product yet.” Build your inventory, define your threat model, and implement controls using your IAM stack (Okta, AWS IAM, GCP IAM) and open-source policy engines (OPA, Cedar). Once you have 50+ agents in production and the cost of manual management is clear, revisit the vendor map.
Frequently asked questions
Is AI agent identity the same as service account identity?
No. Service accounts are built for static, predictable behavior: call the same endpoints with the same parameters, day after day. Agents are built for dynamic, adaptive behavior: decide what to do based on input, context, and model outputs. A compromised service account means the secret leaked. A compromised agent could mean the secret leaked, or it could mean the prompt was poisoned, or a tool returned corrupted data. The defenses are related but not identical.
Can we reuse our existing service-account model for agents?
Not without modifications. Your service-account provisioning assumes roles are static (this account can call these endpoints, forever). Agent authorization needs to be temporal and contextual (this agent can call these endpoints, for this task, until this date, under these conditions). If you only have RBAC, you’ll need to add attribute-based or context-aware rules before agents are ready. The effort is real but doable; it’s the layer between authentication and the agent itself.
Can we use OAuth for agent-to-agent authentication?
No. OAuth is designed for human user flows (browser redirects, consent screens, user interaction). Agents need credentials issued and rotated programmatically, with no human in the loop. Use OAuth 2.1 client-credentials (agent-to-authorization-server) to get a short-lived token, then use that token for agent-to-tool requests. Or use SPIFFE/SPIRE for certificate-based authentication. Both are designed for machines.
What identity does a sub-agent inherit from an orchestrator?
Sub-agents should not inherit the orchestrator’s credentials. The orchestrator should issue new credentials to the sub-agent, scoped narrower than the orchestrator’s own scope. Orchestrator (principal_A) with read-write access to candidates and candidates_private, spawns sub-agent_B: sub-agent_B gets read-only access to candidates (not candidates_private). The audit trail shows “A initiated, B executed with scope X.” If B is compromised, A is not automatically compromised.
How do we rotate credentials for an agent that’s running in real time?
For OAuth 2.1 tokens, use the refresh token pattern: the agent stores a short-lived access token (1 hour) and a longer-lived refresh token (days). When the access token expires, the agent refreshes it automatically without stopping. For SPIFFE/SPIRE, certificates renew automatically (agents check with SPIRE every 1-2 minutes for a new cert); rotations happen without agent restart. For API keys, rotation is hard when the agent is running; this is a reason to migrate away from them. Plan for downtime or use a canary approach (issue new key, run agent with both, verify it works, revoke old key).
How do we detect that an agent is compromised so we know when to revoke?
Three signals: (1) authorization policy violations (”the hiring agent tried to call the payroll API”), (2) unusual request patterns (”the agent made 10x its normal API calls in 1 hour”), (3) access outside normal scope (”the agent read salary data when it usually doesn’t”). You need structured logging to detect these. Build alerts for each signal; map them to your IR process. When an alert fires, triage: is this legitimate new behavior (policy was wrong), or is the agent compromised? Decide whether to revoke, adjust the policy, or investigate.
Related reading
02-pillar-agentic-ai-security, Agent identity is one component of a complete agentic security posture
05-cluster-mcp-security, MCP servers need identity and authorization; NHI principles apply
07-cluster-ai-red-teaming, Red teaming should include identity assumption and credential compromise scenarios