
EU AI Act Compliance: What CISOs Actually Need to Do
The Act is half-enforced and fully confusing. What applies to you, what to do first, and what's safe to deprioritize.

The EU AI Act started enforcing on February 1, 2025. That was four months ago. Your legal team probably sent you a memo. It probably contained the words “high-risk,” “prohibited,” “GPAI,” “Article,” and “substantial non-compliance,” and may have concluded with “discuss with CISO.” Then nothing happened because the memo was written for lawyers, not for security ops.
This is the CISO-only filter. I’m not going to walk you through the regulation’s 27 chapters or the nine implementing regulations that are still rolling out. I’m going to tell you what actually lands on your desk, what your legal and compliance teams need from you, what you can safely ignore for now, and what the failure modes actually cost.
The core tension: the EU AI Act is a product regulation, not a data protection law. It’s about what AI systems do, not about data processing. That means parts of it matter to you immediately, parts matter to your engineering leadership, and some parts are in a jurisdictional limbo until the Irish DPA and NIST finalize guidance nobody’s published yet. We’re going to sort that out.

The parts of the EU AI Act that actually land on the CISO’s desk
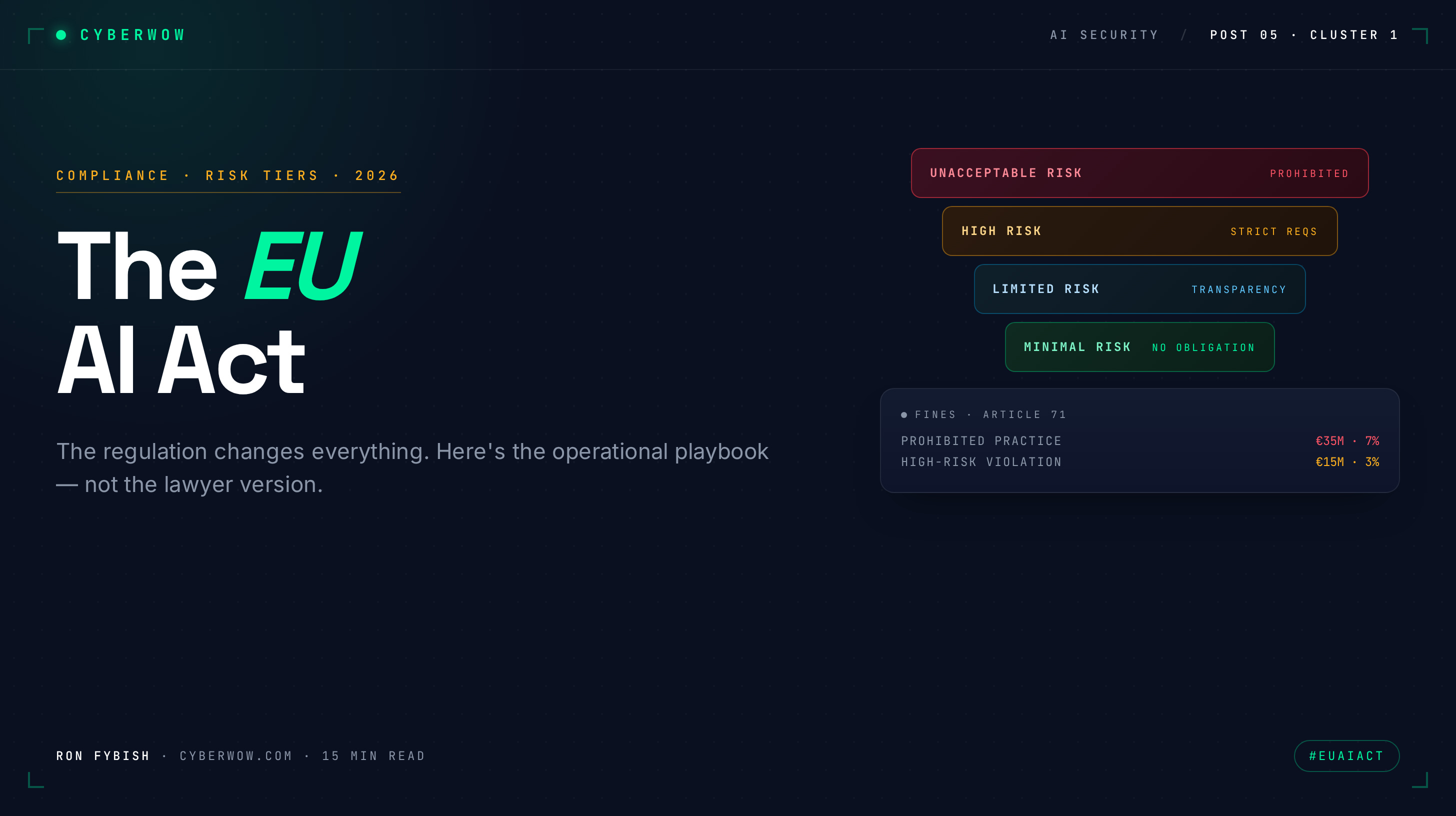
The regulation has four major risk tiers: prohibited AI, high-risk AI, GPAI (general-purpose AI), and everything else. Your CISO obligations cluster around two of them.
Prohibited AI: The regulation bans a narrow set of AI uses outright, mass surveillance, real-time facial recognition in public spaces (with narrow law-enforcement carveouts), emotion recognition in schools or workplaces, manipulation of human behavior to bypass informed consent. Unless you’re a government running a surveillance state or a corp deploying manipulative content filters, this doesn’t apply to you. Your legal team will flag this. You can move on.
High-risk AI: This is the category that matters. High-risk systems include AI used for recruitment, loan decisions, healthcare, educational placement, biometric ID, infrastructure critical-functions, and law enforcement. If you’re a mid-market company, you likely have some high-risk AI in scope: maybe an automated resume screener, a fraud-detection system, anything biometric. For every high-risk system your company operates or places in the market, the regulation requires:
Technical documentation (Article 11), a record of the system’s architecture, data, training, testing, and performance metrics.
Logging and traceability (Article 12), the ability to trace what the system did, when, and why.
Human oversight (Article 14), humans in the loop for high-stakes decisions.
Transparency (Article 13), disclosure to affected users that they’re interacting with AI.
GPAI: General-purpose AI is any foundation model that can be adapted to a range of downstream tasks. ChatGPT, Claude, Gemini, Llama, these are GPAI. By March 2025, the regulation extended obligations to GPAI providers and, more important for you, to companies that integrate GPAI into their own systems. If you built an agent that uses Claude to help with hiring decisions, your deployment is now a high-risk system and you’ve integrated GPAI. Both obligations apply.
High-risk AI systems: the definition in plain English
The regulation’s legal definition of “high-risk” is procedurally defined: the system must fall into one of nine categories and be used for one of the regulated purposes. It sounds bureaucratic because it is. Here’s what it means in practice.
A resume screener is high-risk. It’s in the “biometric identification and categorization” category (you’re assessing employment qualification) and it has a material adverse effect on a person’s livelihood (hiring decisions). The system can’t stay in the market unless you document it, log its decisions, keep humans in the loop for rejections, and tell job applicants they’re being evaluated by AI.
A ChatGPT-powered customer-support agent is not high-risk unless it’s making decisions with a material adverse effect. If it answers questions, it’s not high-risk. If it approves credit or denies a claim, it is.
A fraud-detection system in payment processing is high-risk. Fraud detection is in the “critical infrastructure” category, and a false positive can lock a customer’s account.
The pattern: if your AI system makes a decision about a person’s access to a service, credit, employment, or legal status, and that decision has material consequences, it’s probably high-risk. If it’s purely informational (summarizes, recommends, analyzes), it’s probably not.
For your company: go through every AI system in production and ask, “Does this make a decision that affects a person’s life or access?” If yes, assume it’s high-risk until you have a reason to conclude otherwise. Your legal and compliance teams should do the formal classification, but you need to know what’s in your estate.

The technical documentation obligation (Article 11) for CISOs
This is the first thing your engineering teams will ask you about because it’s the first thing they have to deliver.
The regulation requires “technical documentation” for high-risk systems. The EU hasn’t published a template (they’re still arguing about it), so the de facto standard is the draft regulatory technical standards (RTS) and ISO/IEC 42001, which is the operational AI management standard and the only one that passed regulatory scrutiny in the EU.
What you need to document for each high-risk system:
System design and architecture, what the system does, what inputs it takes, what outputs it produces, what models or sub-systems it uses.
Data used for training and testing, where the training data came from, how representative it is, any known biases or limitations.
Model performance and evaluation, accuracy metrics, fairness metrics, performance across demographic groups, edge cases, failure modes.
Human oversight procedures, how humans monitor the system, what conditions trigger human review, escalation paths.
Security and privacy measures, how the system is protected against attacks, how user data is handled, retention policies.
Monitoring and maintenance plan, how the system is updated, how degradation is detected, how you know when to retire it.
This is not a one-time deliverable. It’s a living document you update every time the system changes. The regulation expects you to keep it current and produce it on demand to regulators.
For your CISO role: You own the security and privacy sections (item 5 above). Your engineering and data teams own the rest. But you need to understand the full picture because these components interact. A training dataset that’s too narrow (item 2) creates a security problem: the system fails in unexpected ways when it encounters data outside the training distribution, and that failure can be exploited. You need to know this when you’re scoping logging requirements (next section).
Concrete artifacts you need to produce
Most teams ask, “OK, so what documents do we actually create?” Here are the six artifacts regulators will ask for in an audit:
1. Model Card, A structured summary of the model’s intended use, training data source, performance benchmarks (accuracy, precision, recall), and known limitations. Your data science or ML ops team owns this. One page to two pages per model.
2. Data Governance Documentation, Where did the training data come from? Is it licensed? How representative is it of the population this system will serve? What labeling was applied and by whom? What quality checks happened? Your data team and legal team co-own this. This document catches biases that lead to fairness failures and legal exposure.
3. Risk Assessment, A structured analysis of failure modes and their consequences. What happens if the model’s confidence drops? What if it makes a biased decision against a protected class? What’s the blast radius? You lead this, working with engineering. This is what regulators actually want to see, evidence that you’ve thought about what can go wrong and you have a plan.
4. Human Oversight Mechanisms, Document the rules that trigger human review. For a hiring system: if confidence is below 75%, a human reviewer sees it. If the system’s decision conflicts with resume screening scores, escalate. For a fraud detector: blocks above $10k go to review; unusual customer profiles go to review. You own the design of these rules; the ops team implements them and maintains logs of when they fire.
5. Accuracy and Resilience Metrics, Raw numbers from testing. Accuracy overall. Accuracy per demographic group (to catch disparate impact). Performance on out-of-distribution data (how does the system behave on inputs that don’t match the training distribution?). Performance on adversarial inputs. Your ML team owns the testing; you own the decision of what metrics matter for security.
6. Monitoring and Incident Response Plan, How do you detect when the system is degrading? What’s your alert threshold? If the system starts making systematically biased decisions, how fast can you take it offline? How do you notify affected users? This is pure security ops. Document it like you’d document an incident response playbook for any other system.

Logging and traceability (Article 12), what “good” looks like
High-risk systems must produce logs that allow regulators and affected users to understand what happened. For each high-risk system, you need to be able to answer:
What decision did the system make, and when?
What data did it use as input?
What rules or models did it apply?
What was the output, and did a human review it?
Who was affected, and how were they notified?
If a resume screener rejects a candidate, you need to log: candidate name, submission time, resume features considered, model confidence, whether it went to a human reviewer, whether the human overrode the system, what the final decision was, and that the candidate was told they were evaluated by AI.
This is where your SIEM and audit infrastructure comes in. High-risk systems need logging at a different granularity than normal application logs. Normal logs record “system event X happened.” AI system logs need to record “decision X was made about person Y based on factors Z and was reviewed by human H.”
Most companies don’t have this logging infrastructure yet. This is the highest-ROI investment for EU AI Act compliance in 2026: design and implement specialized logging for high-risk AI systems. Once you have that, everything else (transparency, audit, incident response) becomes feasible.
Minimum viable log schema for high-risk AI systems
You need to capture these fields for every decision the system makes:
FieldPurposeRetentiontimestampWhen the decision was made3 yearsdecision_idUnique identifier for this decision (for audits)3 yearssubject_idWho or what the decision affectedPer applicable law (GDPR for EU residents: 3 years or longer)system_nameWhich AI system made the decision3 yearsmodel_versionModel version in use at decision time3 yearsinput_featuresStructured data the system saw (can be hashed if it contains PII)3 yearsmodel_outputRaw output (confidence score, ranking, etc.)3 yearssystem_decisionWhat the system decided (approve, reject, etc.)3 yearshuman_review_triggeredWas this decision reviewed by a human?3 yearshuman_reviewer_idWho reviewed it (anonymized if needed)3 yearshuman_decisionWhat the human decided (if different from system)3 yearsfinal_decisionWhat actually happened (system or human)3 yearsnotification_sentDid the subject receive notice of AI use?Depends on regulationexception_flagDid anything unusual happen? (model confidence low, feature out of range, override, etc.)3 years
Retention baseline: Three years is the EU AI Act minimum for audits. GDPR may require longer retention for certain data. Check with your legal team on the applicable standard for your jurisdiction and data type.
Integration with your SIEM
Most large companies have Splunk, Datadog, or Panther already. You can pipe AI system logs into these tools using standard log forwarding (syslog, HTTP event collector, etc.). The challenge is structure: your general-purpose SIEM isn’t optimized for decision traceability, so you’ll need to:
Create dedicated index/pipeline for AI system logs in your SIEM
Enrich logs with business context (link decision_id to subject_id, attach human reviewer names, flag policy violations)
Set up alerting for exceptions (model confidence drops below threshold, human overrides spike, subjects file complaints)
For ML-specific observability: Tools like Arize, Fiddler, and WhyLabs are built for this. They ingest model predictions + ground truth, detect data drift, fairness degradation, and performance drops. If you’re deploying high-risk models, a tool like this is worth the cost. Your SIEM won’t catch “the model’s accuracy dropped 5% for Hispanic applicants” because your SIEM doesn’t know about demographic stratification.
For agents and LLM systems: This is harder. LLM-based systems don’t always produce deterministic decision traces. Log what you can: the user query, the system’s response, whether a human reviewed it, and any flags. Document the limitations in your Article 11 technical documentation.
The technical challenge: High-risk AI systems, especially those using generative models or agents, don’t always produce reproducible decision traces. If an LLM-based system makes a decision, you can’t always trace “which part of the training data caused this output.” You need to log the input the system saw and the output it produced, and that’s what you can audit. The EU is gradually accepting this limitation, they can’t require decision traceability for systems where it’s technically infeasible. But you need to be explicit about what you can and can’t trace, and your documentation (Article 11) is where you explain that.
The four compliance states you can be in
Before we talk about timelines, you need to know which state your company is in. These are not lawyer terms, they’re operational states that determine what your CISO roadmap looks like.
State 1: Not in scope, You offer no AI to EU users, you don’t process EU resident data in AI-mediated decisions, and your entire AI estate is internal-only tools used by your own staff who aren’t in the EU. Compliance burden: zero. You should still have an AI security program (see Pillar 2), but the EU AI Act is not your problem. (If you think you’re here, ask your legal team; most companies aren’t.)
State 2: GPAI deployer only, You use a large language model (ChatGPT, Claude, Gemini) in products or services, but you’re not training your own models and you’re not deploying high-risk systems. You have obligations around transparency (disclosing AI use to users) and possibly copyright compliance. You don’t have technical documentation or logging obligations (those fall on the GPAI provider). Your to-do list: audit which deployments use GPAI, ensure disclosures are in place, verify you have terms of service clarifying that users are interacting with AI. Timeline: your disclosures should be live now (February 2025 enforcement).
State 3: Deployer of high-risk AI, You offer or operate at least one high-risk AI system (hiring tool, fraud detector, credit decisioning, medical AI, etc.) but you didn’t build the model yourself. Your obligations: technical documentation, logging, human oversight, transparency. Your vendor (if you’re using a third-party platform) may provide some of these, but you own the system’s behavior in production, so you own compliance. Your to-do list: audit which systems are in scope, design logging infrastructure, document your deployment, set up human oversight rules. Timeline: you need this shipping by August 2026 at latest, ideally well before.
State 4: Provider of high-risk AI, You trained or fine-tuned the model yourself and are offering it to other companies. You have GPAI provider obligations (transparency, copyright) and high-risk obligations (documentation, logging, oversight). This is the heaviest burden. Your to-do list: everything above, plus: model cards, training data documentation, third-party audit readiness. Timeline: August 2026 minimum.
Most mid-market companies are in State 3. Know which state you’re in before you allocate resources.

The July 2026 deadlines that are actually landing
Here’s what matters: concrete dates. Regulators publish penalties on the enforcement dates, not the draft dates. Here’s the timeline that’s binding law:
PhaseDateWhat’s enforceableArticlesCISO actionPenalty (non-compliance)Phase 1: Prohibitions & GPAI transparencyFeb 1, 2025Prohibited AI systems; GPAI provider transparency5-6Disclosure of AI use to end usersUp to EUR 35M or 7% global revenuePhase 2: GPAI obligations; early high-riskAug 1, 2025All GPAI transparency obligations; risk assessment requirements for high-risk systems8-10Complete risk assessment for each high-risk system; begin documentation; design loggingUp to EUR 15M or 3% global revenue (GPAI); up to EUR 20M or 4% (high-risk)Phase 3: High-risk full complianceAug 1, 2026Technical documentation, logging, human oversight, transparency for all high-risk systems11-14Live technical documentation; live logging infrastructure; human oversight rules enforcedUp to EUR 20M or 4% global revenuePhase 4: Full applicationAug 1, 2027EverythingAllFull compliance audit-ready stateAll penalties enforceable
The August 2026 deadline is the one that matters for CISOs. If you have a resume screener, fraud detector, or any high-risk system in production, it needs documentation, logging, and human oversight by then. Missing this date doesn’t automatically trigger a fine, but it makes you the target for a regulatory audit.
Penalty exposure in concrete terms:
Prohibited systems (rare; you probably don’t have these): EUR 35 million or 7% of global turnover, whichever is higher
High-risk non-compliance (missing documentation, logging, or oversight): EUR 20 million or 4% of global turnover
GPAI transparency/copyright failure: EUR 15 million or 3% of global turnover
Administrative violations (missing reports, obstructing inspections): EUR 10 million or 2% of global turnover
For a $1 billion company, 4% is $40 million. That’s real money. For a $500 million company, it’s $20 million. This is not a “nice to have”, it’s a material risk.
What to deprioritize:
The regulation also covers “low-risk AI” with transparency requirements, basically, any AI system should disclose to users that they’re interacting with AI (unless it’s obvious, like a voice assistant). This is useful guidance but is the lowest enforcement priority. If you’re down to this concern, you’re ahead of 90% of companies.
The implementing regulations on GPAI providers are still rolling out (the EU is still writing RTS on copyright compensation for model training, responsibility allocation between providers and integrators, and systemic risk). Once they land, you may have obligations around third-party AI audits or conformity assessments. For now, that’s on the future roadmap.
ISO/IEC 42001 and EU AI Act: what maps, what doesn’t
Your board or CIO might push back: “Can’t we just get ISO 42001 certified and call it done?” The answer is qualified yes, but certification alone is not sufficient.
ISO/IEC 42001 is an operational standard for managing AI risks. The EU AI Act is a regulatory compliance standard. They’re adjacent but not identical. Here’s what matters:
What ISO 42001 covers that the EU AI Act requires:
AI governance and roles (4.1): Maps to Article 22 (provider governance)
Risk assessment and management (5.3, 5.4): Maps to Article 8 (risk assessment for high-risk systems)
Data governance (5.5): Maps to Article 11 (data documentation)
Documentation and traceability (5.8, 5.9): Maps to Articles 11-12 (technical documentation and logging)
Human involvement and oversight (5.10): Maps to Article 14
Monitoring and performance evaluation (5.11): Maps to ongoing compliance monitoring
If you are ISO 42001 certified, you have much of the operational machinery the EU AI Act expects. Regulators view certification favorably in audits.
What ISO 42001 does NOT cover that the EU AI Act requires:
GPAI-specific transparency obligations (Article 6), ISO covers general transparency, not GPAI model-card standards
Prohibited AI enforcement (Article 5), ISO is not a prohibition mechanism
Systemic risk assessment for GPAI (Article 24), Too early for most companies
Specific penalty thresholds and timelines, ISO is not a legal compliance framework
Bottom line: ISO 42001 certification is an enabler and a strong signal of maturity. It reduces the burden of proving compliance. But it is not a substitute for the specific technical documentation (Article 11) and logging (Article 12) required for each high-risk system. You still need those. Treat ISO 42001 as foundational; EU AI Act compliance as specific.
Many auditors will ask: “Are you ISO 42001 certified?” If yes, they’ll skim some sections. If no, they’ll audit more deeply. Getting certified is worth the effort if you have 2+ high-risk systems in production.

The CISO’s action list for the next 90 days
Audit. In the next 30 days, enumerate every AI system in production (internal and third-party) that makes a decision affecting a person’s access, credit, employment, or legal status. Distinguish high-risk from everything else. Work with legal to formalize the classification.
Logging. For every high-risk system, document what you can currently log about system behavior (input, output, human review, decision). Identify gaps. Design a logging infrastructure for the ones that don’t have it. This is the 60-day priority.
Documentation. For each high-risk system, coordinate with engineering and data teams to assemble the technical documentation. Don’t wait for a template, use ISO 42001 as the benchmark. This is the 90-day target, though you may miss it for complex systems (it’s OK to file a roadmap with regulators if you’re close).
Governance. Draft (or update) an AI governance policy that covers high-risk systems: who can deploy a high-risk system, what documentation is required, what logging is non-negotiable, when human review is triggered. File it with your legal and compliance teams.
Incident response. For high-risk systems, document what happens if the system fails, makes a biased decision, or is compromised. What’s your notification procedure for affected users? How do you communicate with regulators? This belongs in your IR playbook now.
This is the EU AI Act minimum, not the whole thing. But if you ship these five items in the next 90 days, you’re in defensible territory when inspections come.
Frequently asked questions
Is our ChatGPT Enterprise deployment in scope?
Depends on what you use it for. If you use ChatGPT Enterprise to answer customer questions, no, you’re a GPAI deployer with transparency obligations only. If you integrate it into a hiring tool that makes employment decisions, or a credit decision system, or a fraud detector, yes, the combined system becomes high-risk. Your classification depends on the use case, not the model. ChatGPT can be deployed in high-risk or low-risk ways. The distinction matters for documentation and logging burden. ChatGPT Enterprise offers some compliance conveniences (data retention, audit logs), but it doesn’t solve the high-risk problem. You still need your own technical documentation (Article 11) and your own logging (Article 12) if the downstream use case is high-risk. (Note: This is a CISO concern, not a legal question, ask your legal team to formalize the classification of each deployment.)
What’s the minimum documentation to survive an audit in 2027?
Assume an auditor will ask for one document per high-risk system: a consolidated technical documentation file with these sections: (1) system purpose and scope; (2) training data source and representative bias analysis; (3) model version and performance metrics (accuracy, fairness across demographic groups, edge case failures); (4) human oversight rules (what triggers review, who reviews, escalation path); (5) logging schema and infrastructure (what’s logged, retention period, how to retrieve it); (6) incident response (what happens if the system fails or makes a biased decision, notification timeline). This is 8–12 pages per high-risk system. You don’t need a separate model card, data governance doc, and risk assessment if you fold them into this one artifact. Just make sure it’s current (updated within 6 months of an audit) and that you can produce three months of logs on demand. That’s “minimum viable.”
Does the AI Act apply to our internal-only AI tools?
Only if they affect EU residents. If you have an internal hiring tool used only by your US team, with no EU applicants, no, it’s out of scope. If you use the same tool to screen EU job applicants, yes, it’s in scope for EU applicants only. You may need to segment your system or document what controls exist for the EU-affected portions. If you use an internal fraud detector that affects EU customers’ accounts, yes, it’s in scope. Internal vs. external is not the gating question; affecting EU residents is. This is worth a conversation with your legal team because you may have inherited legacy systems that process EU data in ways that nobody documented.
What happens if we miss the August 2026 deadline?
Regulators won’t send the police. Missing the deadline doesn’t trigger immediate fines. What happens is: regulators audit at their discretion, usually triggered by a customer complaint, a public incident, or routine industry sweeps. If they find you operating a high-risk system without documentation or logging, they issue a notice of non-compliance and give you 90–180 days to fix it. If you fix it in that window, fines may be reduced or waived. If you don’t, they escalate to formal penalties. The real cost of missing is the audit itself (legal costs, disruption, required remediation under oversight). Meet the deadline and you stay off the regulator’s radar. That’s the operative incentive.
Do US-based companies need to comply with the EU AI Act?
Yes, if you offer AI systems or services to users in the EU or if your systems process EU residents’ data in the course of making high-risk decisions. “To users in the EU” is broad, if your SaaS product is available to European customers and uses AI, you’re probably in scope. Geofencing (blocking EU access) is the only way to opt out, and most companies don’t choose that. Your legal team can narrow this, but assume yes unless there’s a clear reason not to.
Can ISO 42001 certification satisfy the EU AI Act requirements?
ISO 42001 compliance is a strong signal of operational maturity, and regulators view it positively. But certification alone doesn’t satisfy the regulation, you still need the specific technical documentation (Article 11) and logging (Article 12) for each high-risk system. ISO 42001 is an enabler, not a substitute. The regulation is moving toward “if you’re ISO 42001 certified, you get credit for compliance,” but that’s not law yet. Think of certification as a foundation; the regulation requires you to build the floor on top of it.
Related reading
02-pillar-agentic-ai-security, Understanding where agentic AI systems fit into your compliance picture
06-cluster-shadow-ai, Shadow AI creates undocumented high-risk systems; governance matters
10-cluster-llm-dlp, Data leakage from AI systems compounds EU AI Act risk