
AI SOC: The Business Case for Autonomous Security Ops
Vendors promise 80% analyst offload. The honest ROI math, what actually gets automated well, and what every pitch gets wrong.

Every SOC vendor pitch in 2026 starts with the same number: “Reduce analyst headcount by 80% while improving alert accuracy.” It’s a clean promise. Your Tier-1 analyst is currently burying good alerts in 10,000 noise alerts per day. An AI SOC system learns from the noise, prioritizes the signal, and automates triage. Tier-1 shifts to exception handling. Everyone wins.
The pitch is not technically wrong. But it’s wrong for 90% of enterprise SOCs. The version that works involves restructuring the team, changing how you ingest data, accepting that some alert types don’t automate well, and building process for a fundamentally different operational model. It’s not a tool you bolt on. It’s a replacement of the operating model itself. That’s why most AI SOC deals stall at POC, the pilot works fine in isolation. The deployment doesn’t work because you’re trying to graft it onto a team and a workflow it was never designed for.
This guide is the honest math. What AI SOCs automate well. What they don’t. What the ROI actually looks like. And what you need to do to make it work.
The AI SOC promise (and the honest version)
Here’s what AI SOC vendors demo: A security event arrives. The AI system enriches it (is the source IP known malicious? is the destination a known C2?), correlates it with other events (are there lateral movement signals?), assigns it a severity (confidence 87%, MITRE ATT&CK mapping, impact assessment), and routes it. Tier-1 analyst sees three highly-enriched, deduplicated, contextual alerts instead of 10,000 raw events. The analyst spends 2 minutes per alert instead of 20 seconds skimming noise. The analyst clears their queue and goes home on time.

Here’s the honest version: AI SOC systems are very good at applying rules faster than humans and surfacing statistical anomalies that humans miss. They are mediocre at: reasoning about novel attack chains, disambiguating business context (is this user supposed to be running PowerShell at 3am? depends, are they an ops engineer on-call?), and deciding that something is not a security problem even though it matches a detection rule. They are terrible at: explaining why they rated something as high severity, calibrating for your environment (every environment is different, and the demo was based on a publicly-available dataset that looks nothing like your network), and handling the long tail of legitimate-but-weird activity that doesn’t fit any pattern.
Most AI SOC implementations stall because the team discovers: the AI is really good at validating that an alert that looked bad actually is bad. It’s mediocre at dismissing alerts that are annoying-but-legitimate. And the “80% analyst offload” assumed the noise alerts could be automatically dismissed. In practice, 60% of the alerts need some human judgment call. The AI took the drudge work out (re-checking IP reputation, correlating events), but the judgment calls didn’t disappear, they just moved one layer up. You end up with a team where Tier-1 is now Tier-1.5: trained to think like an AI prompt (here’s the enrichment, here’s the ML confidence score, is this a threat?), reviewing fewer alerts but in more depth.
The ROI is still positive if you expected that, budgeted for it, and reshaped the team accordingly. The ROI is negative if you expected to cut 80% of headcount.

What AI SOCs automate well (and poorly) in 2026
Platform systems in 2026 (Prophet Security, Intezer, Simbian, Torq Hyperautomation, Dropzone AI, Tines, Radiant Security, Anvilogic) fall into two camps: AI-augmented SOAR platforms that add AI to orchestration, and AI-native SOC systems that start with AI and add orchestration. Both are production-ready for specific threat categories. Both have sharp edges on others. Here’s the honest automation breakdown:
What automates well (70-95% success rate)
Enrichment and deduplication (85-95% accuracy). Querying reputation databases, pulling context from threat feeds, and grouping related alerts is exactly what large language models and correlation engines do well. A human doing it takes minutes per alert. An AI doing it takes milliseconds. A human also gets tired and misses the pattern; an AI runs the correlation the same way on the 10,000th alert as the first. This is the highest-ROI automation in an AI SOC, and it’s where the most time savings happen.
Tier-1 alert triage (70-85% accuracy). Filtering obvious noise from potentially actionable alerts. Systems trained on your environment can separate the daily backup (noise), the certificate renewal (noise), the metrics scrape (noise) from the actual anomalies. In practice, this means your Tier-1 analysts see their queue shrink by 40-60%, which translates directly to time savings. The 15-30% of alerts that the AI marks as uncertain still need human eyes. This is the biggest lie vendors tell: they say the AI handles 80% of triage. In reality, it confidently handles 70% and marks 20% as “probably noise but I’m not sure, you decide.”
Known-good and known-bad classification (90%+ accuracy). If you have clean training data (events you’ve confirmed are malicious, events you’ve confirmed are benign), the AI learns that space and categorizes new events at 90-98% accuracy depending on data quality. This works best for high-volume, low-severity data: brute-force attempts, reconnaissance scans, policy violations, failed authentication storms. Prophet Security and Intezer excel here because they’ve been trained on millions of events.
Playbook execution (95%+ consistency). If you have a runbook (”on suspicious PowerShell activity: check if user is an engineer, check if command is in the allow-list, if both yes then auto-close, else escalate to Tier-2”), an AI SOAR system executes that playbook faster and more consistently than a human. This works for repetitive, rule-based tasks: gathering logs, pulling telemetry, auto-responder actions (kill a process, isolate a host, revoke a session). The consistency is the win here, not the speed.
Multi-step correlation on known patterns (80-90% accuracy). A human looks at 50 events and finds the thread: lateral movement from a known pivot point, credential theft, data staging. An AI system trained on MITRE ATT&CK can map raw events to tactics and techniques and surface the chain. Torq Hyperautomation and Tines do this well, especially when the attack matches a known pattern. Where it falls apart is when the pattern is novel or the environment is unusual.
Phishing email and malware triage (75-90% accuracy). URL reputation, sender analysis, attachment reputation, and payload signature matching are all well-solved problems. An AI system or even a good rule engine can handle these at scale. The errors that remain are mostly advanced phishing (domain-spoofing, lookalike attacks, compromised-account emails), but for high-volume generic phishing, this automation works.
What automates poorly (40-60% success rate)
Context-dependent judgment calls (50-65% accuracy). “Is a database admin querying the user table at 11pm a security event?” Depends. Are they on-call? Is it change-control day? Did they have a ticket? Is the query anomalous for them specifically? An AI system trained on aggregate data says “unusual time, high risk.” A human says “I know Dave, he does this whenever deployment happens.” The AI either requires you to pre-feed it business context (which defeats the “autonomous” pitch), or it flags too much noise. Your best results come from AI that has observed the user’s behavior over time and knows their baseline. Without historical data, this is a coin flip.
Lateral movement hunting (40-55% accuracy). Multi-step attack chains that move from one host to another, especially ones that go dormant between steps, are hard for AI to catch. The AI can spot the individual events; it struggles to connect them into a story without either generating false positives (connecting unrelated events) or missing subtle indicators. Humans who understand network topology and threat patterns catch what AI misses, but only when they’re actively looking.
Insider threat detection (35-50% accuracy). An AI system can spot statistical anomalies: a user accessing files they’ve never accessed before, at unusual hours, in bulk. But the AI can’t know that the user is exfiltrating data as opposed to doing their job. A data scientist pulling a large dataset might look identical to exfiltration on network telemetry. A departing employee might start accessing files to transition their work, not to steal. An AI trained on “normal” behavior flags the deviation; it doesn’t judge the intent. These require humans.
Operator error vs. attack (45-60% accuracy). A user repeatedly mis-typing their password looks like a brute-force attack to an AI system. An AI flags it; a human asks “is this the same person?” and deprioritizes. Prophet Security is getting better at this through behavioral modeling, but it remains a consistent source of false positives. The problem is that real attacks often look like operator error for the first few events.
Novel attack patterns (30-45% accuracy). AI systems detect what they’ve trained on. If your threat model includes a novel attack chain not in MITRE ATT&CK (e.g., a supply-chain attack using your specific vendor integrations, a custom lateral-movement technique your Red team invented), the AI misses it. Humans who know your business and your supply chain see it. This is why mature SOCs run AI systems alongside human hunters, not instead of them. The novelty problem also applies to zero-day exploits and newly-disclosed attack frameworks; there’s a lag between disclosure and training data.
Incident communication and decision-making under novel conditions (40-55% accuracy). An AI can say “this looks like a C2 connection.” A human has to say “this looks like a C2 connection and here’s what we need to do in the next hour to contain it, here’s what you tell the board, and here’s which team owns which part of the response.” AI can surface intelligence. Humans have to move the organization. When conditions are novel (a new type of incident the team hasn’t seen), the AI’s suggestions become less reliable, and humans have to take over.
The honest ROI composition
Use AI for enrichment, deduplication, playbook execution, and known-pattern triage. Pair it with a smaller, more skilled human team to handle judgment calls, context-dependent decisions, and novel threats. You’re not cutting analyst headcount by 80%; you’re shifting team composition. A baseline SOC (20 people, 10 Tier-1 + 8 Tier-2 + 2 management) becomes: 6-8 Tier-1 (down from 10, now focused on judgment), 6-7 Tier-2 (handling more incidents because triage is faster), 2-3 specialized roles (detection engineering, AI tuning), 2-3 hunters (novel threats), 2 management. The 80/20 split is replaced by a distributed model where AI handles the fast, repetitive work and humans handle the slow, judgment-heavy work.
ROI math a CFO will actually accept
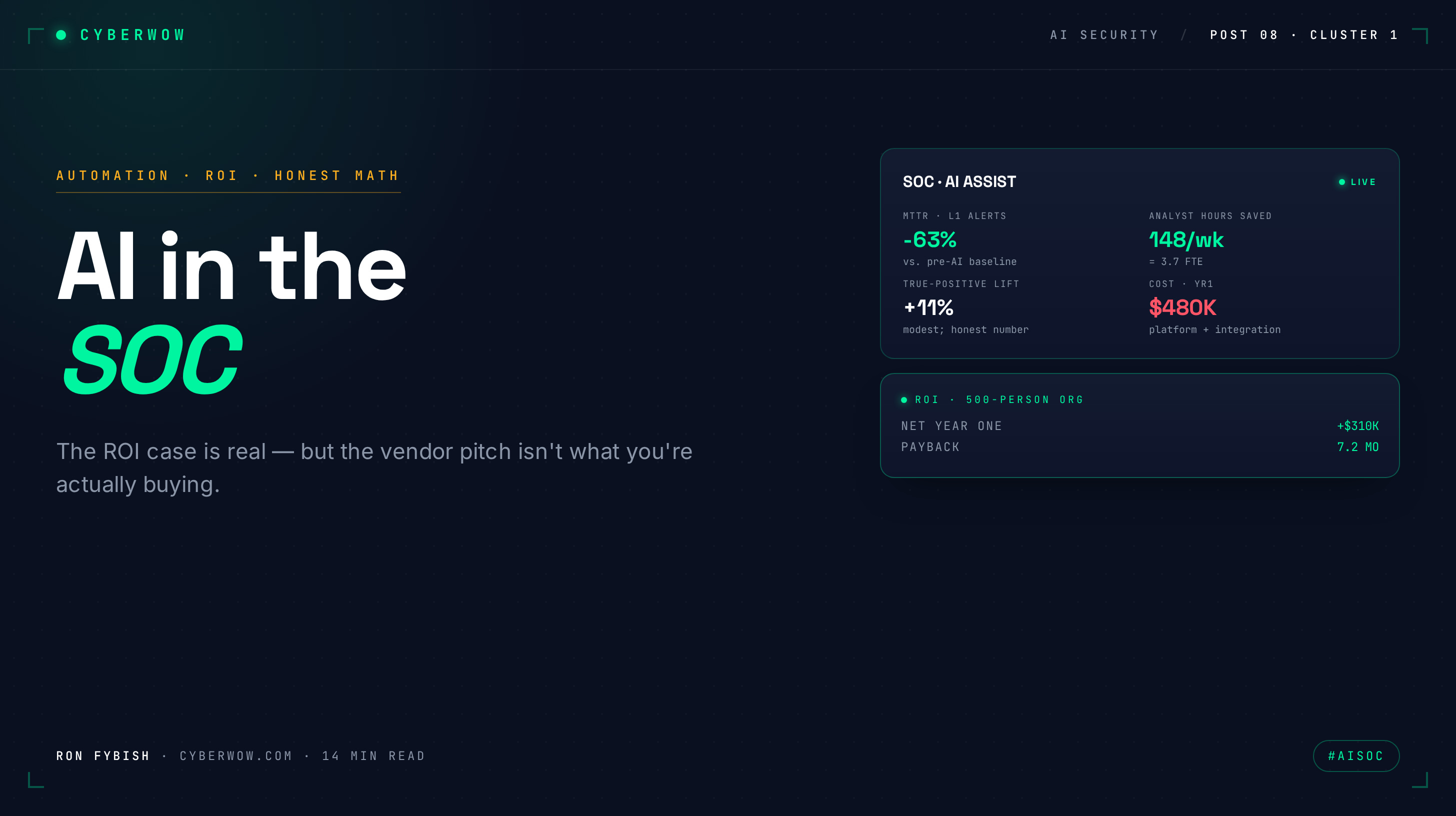
Let’s work through a real scenario. Assume a 500-person organization with a 20-person SOC (typical mid-market ratio). Current operating cost is $2M/year all-in. Annual alert volume is 2M (10,000/day). Here’s the baseline:
Current state (no AI SOC)
Tier-1 team (10 analysts): $800K/year fully loaded (salary + benefits + overhead). Each processes ~200 alerts/day. Signal rate is 5% (real data, not optimistic). That’s 10 actionable alerts per analyst per day, or 100 per team per day.
Tier-2 team (8 analysts): $1M/year. They investigate those 100 actionable alerts, close ~20-30 as resolved or false positive, escalate ~5-10 to incident handling.
SIEM/tools (Splunk, Datadog, Sumo): $300K/year.
Total: $2.1M/year.
Alert closure rate: 20-30 incidents/day. Analyst burnout: high. Overtime: normal.
With an AI SOC (conservative scenario)
Assumptions: You deploy Prophet Security, Intezer, or Simbian. Tier-1 team stays at 10. AI does pre-filtering and enrichment. No dramatic changes to team structure yet.
Tier-1 team (10 analysts): Still $800K/year. But now AI pre-filters the 10,000 daily alerts and surfaces ~1,500 candidates. AI enriches each one (IP reputation, domain history, historical context, rule matches). Each analyst now sees ~150 pre-filtered, enriched alerts/day instead of 200 raw ones. Time per alert drops from 3 minutes to 1.5 minutes (enrichment is done; they’re just doing judgment). Signal rate improves to 20% (the pre-filtering removes low-quality noise). That’s 30 actionable alerts per analyst per day, 300 per team per day.
Tier-2 team (6 analysts): Reduced to $750K/year. They now handle 300 actionable alerts per day (instead of 100). Processing time per alert drops because each one is already enriched and contextualized. They close 50-60 incidents/day, escalate 10-15. Turnover drops because the work is less repetitive.
AI SOC platform: $250K/year (Prophet, Inteizer, Simbian, or Torq license for a 500-person company, cloud-hosted, includes API calls and user seats).
SIEM license (right-sized): $200K/year instead of $300K. You’ve offloaded some correlation work to the AI system, so you can negotiate a smaller Splunk or Datadog footprint.
Detection engineering (0.5 FTE new): $90K/year. You now need someone tuning the AI system, writing custom rules for your environment, feeding it training data. This is mandatory; vendors don’t mention it, but it’s where the engineering work moves.
Total: $1.89M/year.
The math
Cost reduction: $2.1M to $1.89M = $210K/year saved. Payback period on AI platform: $250K upfront + $250K annual = $500K total first-year cost. With $210K in savings, payback is ~2-2.5 years. Headcount reduction: 0.5-1 FTE. You’re down from 18 to 17.5 analysts. Not 80%. Not even close. Operational improvement: Alert closure improves from 20-30/day to 50-60/day. MTTR improves by 30-40%. Tier-1 burnout drops because they’re doing less drudge work.
This is the honest picture. The CFO gets a modest cost reduction ($210K, about 10%) plus significant operational improvement (alert closure +150%, MTTR -40%, turnover reduction). The “80% headcount cut” pitch is gone.
When ROI improves
ROI gets better if:
Alert volume is higher. Every additional million alerts/year adds minimal cost to the AI system but saves more Tier-1 time. At 5M alerts/year, the savings double.
Your SIEM is expensive. Splunk at scale can run $500K+/year. Offloading correlation to an AI system (and switching to a lighter SIEM like Datadog) saves $200-300K.
Your Tier-1 team is high-cost. If you’re in San Francisco or New York where a Tier-1 analyst costs $120K fully loaded, the labor savings multiply. If you’re in a lower-cost market, they don’t.
Tool stack is already messy. If you’re running three separate tools (SIEM + EDR + cloud native), consolidating to an AI SOC that talks to all three reduces licensing complexity and saves money.
Incident velocity matters more than cost. If a 40-minute MTTR improvement prevents one data breach per year, and a data breach costs $4M, the ROI is enormous. Some CISOs can’t quantify this but they know it’s true.
When ROI gets worse
ROI gets worse if:
Your SIEM is already efficient. If your team has spent three years optimizing Splunk correlation and deduplication, the AI system is duplicating work you’ve already done.
Your team is already specialized. If your Tier-1 team is already small (5 people instead of 10) and every person is doing 40% judgment work instead of 80% noise triage, the AI system has less to automate.
Alert volume is low. Under 500K alerts/year, the AI system’s fixed costs dominate. The ROI doesn’t clear.
False positive rate needs to stay at zero. If your environment is so sensitive that a 2-3% false positive increase is unacceptable, the AI system’s margin for error is too tight.
Integration costs are high. If your SIEM has a custom data pipeline and custom rules, integrating an AI system requires re-architecting. That’s 3-6 months of engineering time, which kills the ROI timeline.
How to calculate this for your environment
Take your current SOC operating cost. Measure: (1) alert volume per year, (2) average Tier-1 salary, (3) current SIEM cost, (4) alert closure rate, (5) MTTR. Then run this formula:
Savings from AI SOC = (Tier-1 hours freed * Tier-1 salary/2080) + (SIEM reduction) - (AI platform cost) - (detection engineering cost).
For most organizations with 1M+ alerts/year and $800K+ Tier-1 spend, this formula returns a positive number in year two. For organizations below that threshold, it’s breakeven or negative.
Do the math for your environment. Don’t use the vendor’s numbers. Run a POC and measure your real false positive rate and time savings before committing budget.

Three deployment paths: decision matrix
Most CISOs choose wrong here, and it’s why they end up disappointed. There are three ways to deploy an AI SOC system, and each one has different risk, cost, and timeline profiles. Here’s how to choose:

PathHow it worksRisk levelTimelineCost profileWhen to useFailure modeRip-and-replaceDisable current SIEM alerting. Deploy AI SOC in production. Go live.Very high4-8 weeksLower upfront ($250K Y1) but high risk of downtimeGreenfield SOC or current SIEM is actively failingAI system misbehaves or has model drift. You’re blind for hours while you debug. This happens to 1 in 3 rip-and-replace attempts.Augment (middleware)Keep existing SIEM. Feed alerts to AI system for enrichment. AI re-routes alerts.Low8-12 weeksModerate ($250K + some ops work)Most organizations. Happy with current alerting but drowning in volume.AI system goes down. Fallback: alerts flow to analyst queue unfiltered. No production risk.Parallel (dual-run)Run AI SOC side-by-side with existing pipeline for 3-6 months. Both generate alerts. Team sees both streams.Very low6-12 monthsHighest upfront ($250K + 6mo dual licensing = $400K+) but safestRisk-averse orgs, regulated environments, critical infrastructureTakes 6 months to build confidence. Costs more. Slower time-to-value. But you never have an incident because the AI got something wrong.
Decision framework
Choose rip-and-replace if: - Your current SIEM is failing operationally (crashes daily, can’t ingest your data volumes, outdated technology). - You’re building a new SOC from scratch (no existing pipeline to replace). - You have strong operational discipline and can debug issues in production. - You have a strong vendor relationship with the AI SOC platform and trust their stability.
Choose augment (middleware) if: - You’re happy with your current detection but drowning in false positives. - You need a quick deployment and can’t afford 6 months of parallel runs. - Your risk tolerance is moderate (some degradation acceptable, but not total blindness). - Your team is already at capacity and you can’t staff a parallel evaluation.
Choose parallel (dual-run) if: - You’re in a regulated industry (finance, healthcare, critical infrastructure) where a SOC outage is a compliance incident. - Your CISO seat is new and you’re building credibility. A parallel deployment removes political risk. - You have the budget and the patience. You’ll spend more money but you’ll have zero incidents. - You want to compare AI performance against your human team on the same alerts.
What rip-and-replace actually looks like
Vendors demo this path because it looks clean. In practice: You deploy the AI SOC system Thursday afternoon. Friday morning, it’s in production. Friday 11am, the first weird behavior shows up: the AI system marks 500 alerts as “high confidence C2 activity” that your team knows are background noise. Saturday morning, your team is manually reviewing 500 false positives instead of sleeping. You roll back Sunday. You spend the next two weeks tuning. You go live again. This time it works, but you lost two weekends and your team lost confidence in the system.
One in three rip-and-replace deployments experience a significant issue in the first month. Plan accordingly.
Augment is the safe choice
Most “AI SOC” deployments in 2026 are actually augment, not rip-and-replace. The AI system becomes middleware: it doesn’t replace your detection, it enhances the routing. If the AI system fails, alerts still flow to the analyst queue (just with less enrichment). Your production risk is zero. Your upside is smaller (you get enrichment and pre-filtering, not full replacement), but your downside is also zero.
If your vendor is pushing rip-and-replace, ask why. If they say “because it’s faster,” push back. Faster for them, not for you.
Demo tricks vendors use (and how to counter them)
The vendor demo is a masterpiece of production engineering. The environment is clean. The alert volume is curated. The attack patterns are textbook. It’s not a lie, but it’s not your reality either. Before you sign, know the tricks and ask the counter-questions.

Trick 1: Cherry-picked alert sets
What it is: The vendor shows you 50 alerts from their public test dataset. The dataset is heavily weighted toward “clean” attack patterns that the system is trained on. Real-world SOC data is 70% noise and 20% business-context-dependent, with 10% actually interesting security events.
Counter-question: “What’s your system’s performance on our historical alert data, not a curated set? Can we run a 30-day snapshot of our actual stream and see how many false positives we get on our known-good activity (daily backups, metrics collection, certificate renewals, maintenance windows)?”
Trick 2: Cached reasoning that looks like real-time agent work
What it is: The AI system processes a batch of alerts overnight and caches the reasoning. During the demo, it retrieves the cached answer in 3 seconds and plays it back, making it look like the system is doing real-time reasoning. Real-time deployments are slower and sometimes make different decisions.
Counter-question: “Can you show me the system’s end-to-end latency on a new alert that it’s never seen before? Not a retrieved answer, an actual cold-start decision. And show me your batch-processing vs. real-time decision paths are identical.”
Trick 3: Selection bias in triage accuracy numbers
What it is: The vendor claims “98% triage accuracy.” They’re measuring accuracy on alerts the system is confident about, not alerts it’s uncertain about. If the system marks 60% of alerts as “certain” and gets 98% right on those, that’s not the same as “the system handles 98% of your alerts correctly.” It’s only handling 60% with confidence. The remaining 40% still need human eyes.
Counter-question: “What percentage of alerts does your system mark as ‘uncertain’ or ‘low confidence’ and route to a human anyway? And of the alerts it marks as ‘certain,’ what’s your false-positive rate? And your false-negative rate? Those are different.”
Trick 4: “We handle 5M alerts per day” with no signal/noise breakdown
What it is: Sounds impressive until you realize they mean 5M raw events from a single customer. Those 5M events might produce only 500 unique alerts because of deduplication. Or it might be a customer with a network so noisy that the signal rate is 0.1%. Without knowing signal vs. noise, the number means nothing.
Counter-question: “Of those 5M events, how many unique alerts do you surface? What’s your median false-positive-to-true-positive ratio? And how does that compare to the customer’s previous system?”
Trick 5: “Our LLM understands context” without showing the reasoning chain
What it is: The vendor talks about machine learning and context understanding. You ask how it works. They wave hands. If you can’t see the reasoning, you can’t debug it when it fails.
Counter-question: “Show me your full reasoning chain on one alert from your demo. Not a generic flowchart, the actual output: source IP reputation (yes/no), destination IP known? (yes/no), user baseline for this hour? (normal/anomalous), time-of-day factor (night/weekend/normal), etc. Show me the inputs, the weights, the confidence score, and the final decision.”
How to evaluate AI SOC vendors (the real way)
Before you sign a contract, do these five things:
1. Get references from someone using your exact tool stack. Not “a company similar to you”, someone running Splunk (if that’s you), the same EDR, the same cloud platform. Alert behavior is very specific to how the tools generate alerts. What works on Splunk might not work on Datadog because the formatting is different.
2. Run a POC with your own data. Use a 30-day snapshot of your actual alert stream, your actual tools, your actual alert volume. Does the system handle your custom rules? Does it understand your on-call schedule and maintenance windows? Does it learn from your feedback? Most importantly: does it reduce your false positive rate or just shuffle the deck? A good vendor will support this without trying to water down the dataset.
3. Have Tier-1 analysts evaluate the UX, not just engineers. The engineer cares about APIs. The analyst cares about: “Can I understand in 30 seconds why the system flagged this? Can I tell it it’s wrong and will it actually learn?” Vendor UIs are often engineered for executives (pretty, high-level) and miss what operators need (speed, clarity, feedback loop).
4. Test on your known false positives. Pull 100 alerts your team knows are benign: the daily backup, the certificate renewal, the known scan. Feed them to the system. If it deprioritizes less than 70% of them, it will generate more noise than signal until it’s trained on your environment. A system that labels your daily backup as “possible data exfiltration” is worse than your current alerting.
5. Ask for the actual detection logic on one alert. Not “we use machine learning to assess context.” That’s a non-answer. What you want: “On the lateral-movement alert, we checked: source IP in attacker DB (yes), destination host has recent admin logon from that IP (no), connection matches C2 signature (no), confidence: 63%, recommendation: investigate.” If they can’t show the chain, it’s a black box.
6. Ask for their MTTR improvement data from existing customers. Not “faster alerting” in the abstract. Actual data: “Our median MTTR went from 45 minutes to 28 minutes, and false-positive review time dropped by 35%.” Vague claims are worthless. Specific numbers you can compare to your baseline matter.
Most AI SOC contracts stall at step 2 or 4: the demo works great, but your data is different and the system underperforms. Make sure both you and the vendor understand your environment before you commit budget.
Frequently asked questions
Does AI SOC eliminate the need for Tier-1 analysts?
No. It eliminates the drudgework of Tier-1 (rote triage, reputation checking, deduplication). It doesn’t eliminate judgment calls. In a mature AI SOC, Tier-1 shrinks and specializes. You’re not cutting 80% of the team; you’re shifting from 80% undifferentiated triage work to 50% triage + 30% specialized roles (detection engineering, tuning) + 20% hunting. The skills required also shift: instead of “can you read an alert,” the bar becomes “can you understand why the AI made that decision and push back if it’s wrong.” That’s a harder skill to hire for, not an easier one.
Can AI SOC handle custom detection rules?
Depends on how custom. If your rule is “alert on lateral movement with three hops,” most systems can ingest it. If your rule is “when this cloud app container deviates from peer baseline in ways we’ve defined locally,” you’re looking at months of tuning before the AI understands it. The issue is that custom rules usually encode domain knowledge specific to your environment, and the AI system needs examples to learn that domain knowledge. Budget 2-4 weeks of detection engineering per 50 custom rules you want integrated. If you have 200 custom rules, that’s a problem. If you have 20, that’s manageable.
What’s a reasonable POC length?
Minimum 30 days. That’s one full business cycle (weekdays + weekends + on-call coverage + maintenance windows). Ideally 60 days so you see two full cycles and seasonal variation. By 90 days, you should have enough data to make a go/no-go decision. Anything shorter than 30 days is theater. The vendor wants to go live fast; you want signal. 60 days is the compromise.
How do we trust autonomous triage for the first 90 days?
You don’t trust it fully. Use the augment model: the AI system enriches and pre-filters, but a human always sees the alert before it’s acted on. During the first 30 days, track what the system marks as “high confidence” vs. “uncertain.” Audit the “certain” decisions weekly: did we agree with those? Did we miss anything? Build a confusion matrix (true positive, false positive, false negative, true negative) and measure sensitivity and specificity. If the system’s false-positive rate is under 10%, you’re okay. If it’s over 20%, you need more tuning. By day 90, if the metrics look good and the team trusts it, you can graduate to semi-autonomous (AI auto-closes low-severity alerts below a threshold, routes others for human review).
What’s the biggest mistake CISOs make when deploying AI SOC?
Expecting the system to work out of the box. Every AI SOC system requires tuning on your data. You can’t just point it at your SIEM and walk away. You need: (1) 1-2 weeks of data science work to understand your baseline and train the model, (2) 2-4 weeks of detection engineering to integrate your custom rules, (3) 4-8 weeks of operational tuning where your team gives feedback and the system learns. CISOs who deploy without that preparation see high false-positive rates and abandon the system. CISOs who invest in tuning see real ROI.
What’s a vendor-agnostic overview of the AI SOC landscape in 2026?
Prophet Security, AI-native SOC focusing on behavior modeling and context enrichment. Strong on Tier-1 triage and false-positive reduction. Best for organizations with clean Splunk or ELK deployments.
Inteizer, Originally endpoint analysis, now full SOC automation. Strong on malware classification and known-good/known-bad labeling. Best for organizations with mature endpoint telemetry.
Simbian, Cloud-native SOC, strong on cloud-specific alerts (AWS, GCP, Azure). Handles multi-cloud environments well. Best if you’re cloud-first.
Torq Hyperautomation, SOAR-first with AI add-on. Orchestration and playbook execution are the core. Strong on multi-tool integration. Best if you have complex tool chains and custom playbooks already.
Dropzone AI, Alert enrichment and deduplication focused. Lightweight, works as middleware. Best if you want low risk and minimal infrastructure change.
Tines, Workflow automation with AI. Flexible, good for custom alert routing. Best if you have non-standard alerting logic or custom business rules.
Radiant Security, Incident-focused. Less about alert triage, more about accelerating IR. Best if your team is good at triage but slow at investigation.
Anvilogic, Rules-as-code and correlation engine. Less AI/ML, more deterministic logic. Best if you prefer explicit rules over learned models.
No single vendor is “best.” Choose based on: (1) your current tool stack, (2) your team’s skill level, (3) whether you want AI-first or augmentation-first, (4) your budget for tuning and engineering.
Related reading
The CISO’s Guide to Agentic AI Security, why agent-driven SOCs are a different beast than traditional AI-augmented SOCs
AI Red Teaming: A Methodology for CISOs, how to test an AI SOC system’s resilience before production
Non-Human Identity for AI Agents: The New IAM Frontier, managing the identities and actions of autonomous SOC agents
Building an AI Security Program: Policy to Implementation, how to fit AI SOC into your broader security governance
Agentic AI vs. Traditional Security, understanding how AI SOC requirements differ in agentic environments